二、等值机制
经典测量理论(CTT)与项目反应理论(IRT)都有相应的等值程序与方法。本文后半部分将介绍CTT语境下的三种等值程序。本系列论文的第三篇将介绍IRT的等值程序。本文和第三篇文章提供的信息,目的在于使读者熟悉等值程序的基本原理,而这些都是测量学家在大型测试项目中经常使用的。
1. 平均值等值(Mean Equating)
周密的考试开发、设计和试卷命制要考虑采用一种叫“平均值等值”的程序。使用这种设计,可计算两份试卷的平均值之差。这两份试卷是由随机等值组或平衡单组设计取样的考生完成的。使用平均值之差作为调整,如在一份试卷的成绩加上(或者减去)平均值之差,可以把两份试卷的成绩放到同一量表上。两份试卷都可以作为基础试卷,然后再调整另一份试卷的量表。
要判断得到的平均值之差是由于取样的不同,还是由于试卷的不同产生的,通常是比较困难的。因此,命题与组卷过程要非常谨慎,以控制试卷的差异。这种方法是以此为假设条件的,即由平均值之差预测的试卷量表之差与试卷各个点的成绩分布之差是相同的。这个假设在成绩分布的中心部分是比较合理的,但在高分数段和低分数段范围内,并不总是符合条件。
2.线性等值(Linear Equating)
线性等值是经典测量理论中常用的一种方法,用来决定两份平行试卷的等值分数。线性等值是基于这样的假设,两份待等值的试卷除了它们的平均值和标准差不同外有相似的成绩分布(Crocker&Algina,1986)。
如果两份试卷的成绩和它们各自的平均值距离相等,就可以进行线性等值的成绩匹配,成绩到平均值的距离为标准差(standard deviation)单位。如果两份试卷的原始成绩转化并表示在标准正态Z分数量表上(平均值=0,标准差SD=1),那么线性法就把两个具有相同Z分数的原始分数等值起来。这个步骤比较简单直观,带有很强的假设条件,也比平均值等值更灵活,并且应用了更多的统计信息。
如果转化在标准正态Z分数量表上的成绩一样,那么线性等值法就把试卷A里的成绩“a”和试卷B里的成绩“b”等值起来,即Z(a)=Z(b)。两个分数间的标准线性关系如下:
分数(a)=斜率*[分数(b)]+截距
这里斜率是标准差的比率,截距是试卷A的成绩平均值减去斜率乘试卷B的成绩平均值。线性等值顾名思义就是试卷A的成绩和试卷B的成绩的关系可以用标准线性公式来表示,因此可以在图中用一条直线表达出来。这条直线代表所有成绩之间的等值关系。如图11所示,由平均成绩可以看出,试卷B(新的10道题的试卷)比试卷A(旧的10道题的试卷)显得要难。该例中的平均值之差为2(试卷A平均值=7,试卷B平均值=5)。

图11 线性等值图例
线性等值法假设两份试卷之间仅是平均值和方差的差别。在图11中,各自试卷的成绩如果与平均值(mean)之间的距离(以标准差为单位)相同,就可以视为等值的成绩。线性等值有四个特征会影响对程序的评估以及对结果适当的解释。
第一,试卷A的成绩放在试卷B的量表上(或者反之)的线性转化得到的两份试卷各自成绩之间的等值是一样的,这也称为等值函数具有对称性。因此,必须注意虽然线性等值的方程和回归方程相似,但线性等值并没有像回归方程一样涉及两变量间的相关,而且是对称的。相反,用回归方程法由试卷B的成绩预测试卷A的成绩时,会得到与从试卷A预测试卷B的成绩不同的数值。除非是在两份试卷的分数相关为1时,才是一样的。
第二,在线性等值中各自试卷的成绩为整数,但是等值的成绩很少是整数,而是含有小数位。为处理等值成绩非整数问题,测量心理学家使用了各种方法,把等值成绩取整,以使它们可以报告离散成绩。但是取整也会产生自身的等值误差。
第三,如图11所示,试卷B有个非常高的分数,与之对应的试卷A的分数却在试卷A可能得到的分数的范围之外。图中显示试卷B的10分将与试卷A的11分或者更高分数等值,但这在实际中是不可能的。同样的问题也会出现在成绩量表的低分数端。虽然这些分数没有非常确切合适的等值数值,但是对那些得到满分(或将近满分)或得0分(或将近0分)的考生作出决定是不难的。不管怎样,这都是一个问题,特别是专业人员在解释结果,或者利用整体的统计数据来评估学生进步以及项目的有效性时都需要面对和解决。
第四,线性等值的恰当性(appropriateness)是基于这样的假设,即两份试卷的成绩分布只是在各自的平均值和标准差上不同。但是这个假设条件有时是不成立的,因为成绩分布可以在它们的偏度和峰度发生变化。线性等值精确度在平均值附近相对要稳定,但在高端和低端的成绩量表上会产生变化。
#p#副标题#e#
3.等百分位等值(Equipercentile Equating)
等百分位等值的基础是,如果每个成绩在各自测试中的百分等级相同,就可以对两份试卷的成绩进行匹配。等百分位等值法可以在整个成绩量表上提供相同精确度的等值结果,而且如果试卷在整体难度上不一样,它可以得到比线性等值更精确的结果(Kolen&Brennan)。
利用等百分位等值法是否能得到等值的成绩很大程度上取决于命制试卷时实现等值的程度。“等百分位等值”一词通常用来泛指“匹配成绩”或“两两对应成绩”(matching or pairing score)时采用的方法。但是这个术语应谨慎使用,使用的前提是题目和试卷命制过程满足了等值要求。
等百分位等值的第一步是确定两份待等值试卷的成绩的百分等级(Crocker &Algina),并将在各自试卷上百分等级相同的成绩两两配对等值。表1提供了一个简例,两份10道题的试卷(试卷A和试卷B)采用这种方法实现等值。试卷原始成绩范围为1到10。表中同时显示试卷A和试卷B原始成绩的百分等级。其假设在平衡单组设计条件下,同样的学生做了两份试卷,或者由随机等值组做了两份试卷。
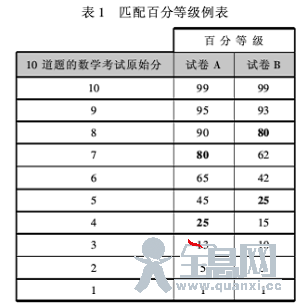
表1的数据表明,如果考生能在试卷A中10题答对7题,那么他的成绩的百分等级是80;而要在试卷B中达到80的百分等级,考生必须答对10题中的8题。这些数据表明,试卷B比试卷A要容易,因为要达到相同的百分位,试卷B要求更高的原始分。同样,考生在试卷A中达到25的百分等级需要答对4题,而在试卷B中则需要答对5题。因此,试卷A的4分等值于试卷B的5分,因为这两个成绩代表各自考试相同的百分等级(等百分位由此得名)。
等百分位等值法是基于表1所示的数据类型,由百分等级来推断两份试卷的等值分。实际操作中常用计算机软件的算法来匹配分数,而考试往往会远超过10道题,同时样本量也通常较大。
等百分位等值的基本原理如图12所示。图12显示试卷A和试卷B分数各自的百分等级。试卷B的6分的百分等级刚达到40,而试卷A的4.75分则可以达到相同的百分位(40)。
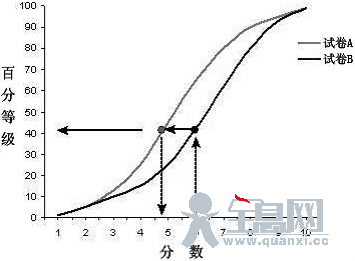
图12 等百分位等值图例
为清楚说明涉及的主要概念,上面的论述简化了等百分位等值法。但同时,必须认清一些复杂的问题。
第一,尽管按照答对题数目得到的学生的成绩是离散的,但这些成绩的分布不是连续的。例如,图12中试卷A的6分等值于试卷B的4.75分,但4.75分这个成绩实际上是不存在的。因此,要解决这样的问题,关键是要取一个整数原始成绩。如原始分4分可以看做一个班级区间在从3.5到4.5之间的中点。4分的百分等级,准确讲就是4分以下的考生比率加上得4分的考生比率的一半(0.5)。用0.5这个系数是因为4分是这个区间的中点,同时假设在这个区间分数分布是均匀的。同样,在其他的整数之间的分数虽然实际上也不存在,但也可以准确地处理。这些步骤涉及到去掉小数位,或取整,都不可避免地会产生一定的误差。
第二,在等百分位等值中偶尔会发生这样的情况,任何考生都没有拿到某个特定的分数,相邻的(0频率和刚好在它之上或之下的)分数具有相同的百分等级。结果,这两个不同的原始分数将在每个测试中等值成同一分数。解决这一问题的普遍做法就是把它们共同(共享)的百分等级放在两个原始分的中点,即原始分的平均值上。Kolen和Brennan提供了0频率问题的另一个解决方案,即在各个成绩上加上一个很小的相对频率,然后调整相对频率,使之总和为1。
第三,在使用等百分位等值法时有一个或两个考试的成绩分布是不规则的。与假设的平滑分布不同,实际分数分布通常显得“崎岖不平”或呈“锯齿状”。这种情况下,随着等值的精度提高,应该使用一些使分数分布平滑的技术。在分数分布中使用平滑技术称为“预先平滑”,而在等值成绩中使用平滑技术称为“事后平滑”。这些步骤在Kolen和Brennan的著作中有详细介绍。
(1)线性等值和等百分位等值的优缺点比较
等百分位等值把两个考试中的所有可能成绩范围等值起来,这解决了线性等值的最大问题(Kolen&Brennan)。另外,在解释试卷A和试卷B的成绩分布的差异上,等百分位等值比线性等值的假设条件更少。但同时,等百分位等值的误差通常比线性等值大(Crocker&Algina)。
使用线性等值或等百分位等值都可以得到等值分数,如果试卷A和试卷B“以相同的信度测量相同的特征,并且与原始分数对应的百分等级相同”(Crocker&Algina),那么试卷A的成绩可以认为是与试卷B的成绩等值的。由于这两种方法具有很多相似性,一些专家认为线性法近似于等百分位法(Hambleton,1991)。
使用二者之中的哪一种取决于很多因素,其中一个主要的考虑是线性等值的假设是否可靠。也就是说,两个待等值的考试之间是否仅是平均值和标准差的差别。较线性等值而言,等百分位等值假设条件更少。所以,如果线性等值的假设不可靠,等百分位等值就可能更精确一些。但是,如果成绩分布相近,线性等值则比等百分位等值更准确(Crocker&Algina)。虽然成绩分布只是平均值和方差的不同,它们也会出现相似的结果。
(2)等值误差:统计和测量心理学程序中的误差方差
连接和等值程序在应用教育测量领域中被广泛使用,但实际上在拟定题目、命制试卷、实施考试、数据分析、使用等值程序等过程中,每一步都使数据发生了变异,产生了众所周知的“误差方差”(error variance)。误差方差的来源至少包括以下方面:题干及问题的表述、测量误差、违反IRT和统计假设的条件、取样误差、等值方差等。
Kolen与Brennan(2004)把在等值中的误差分为“系统误差”和“随机误差”。系统误差指方差来源为试题或试卷命制的差异、违反统计或测量心理学假设的条件以及在考试实施中出现的异常。随机误差指实施等值时采用的考生取样法引起的误差。等值误差通常指取样引起的随机变量误差。
实践中,等值程序通常使用于一个更大的群体。谨慎设计的取样法,如分层按比例随机取样法可以减少取样方差。但是,除非是在所有的考生中使用等值,取样变量误差是难以避免的。预测这个等值误差有两种方法:经验法和分析法。Kolen和Brennan(2004)提出了Bootstrap经验法。在这个方法中,等值步骤在重复的(有所替换)取样中不停复制,所得出的等值成绩的变异可以作为等值误差的估计。这种方法需要大量的计算,而且精确度取决于考生群体大小、样本大小、等值设计和步骤及其他因素。
预测等值误差的分析法也称为Delta法。Delta法为不同的等值设计提供了等值误差的预测公式,其等值程序以统计为基础,如平均值、标准差和累计分布等,并且带有一定的预测误差。Delta法推导出的公式为等值法中涉及的统计标准误差的函数。Kolen和Brennan描述了估计各种等值设计和等值方法的误差的分析步骤。
#p#副标题#e#
参考文献:
[1]Brennan,R.L.(Ed),Educational Measurement,4th ed,Westport,CT:Praeger Publishers 2006.
[2]Crocker,L.,&Algina,J.,Introduction to Classical and Modern Test Theory,Belmont CA:Wadsworth Group,1986.
[3]Dorans,N.J.,Pommerich,M.,&Holland,P.,W.,Linking and Aligning Scores and Scales,Statistics for Social and Behavioral Sciences,New York:Springer,2007.
[4]Hambleton,R.,Swaminathan,H.,&Rogers,H., Fundamentals of Item Response Theory,Newberry Park,CA:Sage,1991.
[5]Kolen,M.J.,&Brennan,R.L.,Test Equating,Scaling,and Linking:Methods and Practices,2nd ed.,New York,NY:Springer,2004.
[6]Ryan,J.,&Brockmann,F,Practitioner's Introductions to Equating with Primers on Classical Test Theory and Item Response Theory,Washing,DC:Council of Chief State School Officers,2009.
[7]Ryan,J.,A Practitioners'Introduction to Equating and Linking with a Primer on Classical Test Theory and Item Response Theory:Major Concepts and Basic Terms,Examination Research,2011(1):80-94.
[8]Sinharay,S.,&Holland,P.,Is It Necessary to Make Anchor Tests Mini-Versions of the Tests Being Equated or Can Some Restrictions Be Relaxed?Journal of Educational Measurement,2007(44):249-275.
[9]Von Davier,A.A.,Holland,P.W.,&Thayer,D.T, The Kernel Method of Test Equating,New York:Springer,2004.
责任编辑:付雷



















