基于经典测量理论和项目反应理论的等值与连接(一)
副标题#e#
约瑟夫·M·瑞安(Joseph M Ryan)博士,1968年毕业于美国波士顿学院的数学系,1969年获得该校教育心理学硕士学位,1977年获得芝加哥大学教育测量、评价及统计分析博士学位。1974—2006年先后供职于美国南卡罗来纳大学及亚利桑那州立大学,分别担任过这两所大学教育学院和教师学院的系主任、中心主任。
瑞安教授从事教育评价和测量咨询专家工作已超过20年。他与美国中小学、学区、州教育部以及考试机构密切合作,为其开展了广泛的教育咨询服务。目前,瑞安博士仍担任了包括阿拉斯加、爱德华、康涅狄格、俄亥俄,德克萨斯,以及华盛顿在内的美国多个州的教育技术顾问委员会(the Technical Advisory Committees)的委员,并参与了超过12个州的教育评价与测试工作。瑞安博士的研究专长有量化、等值、成绩报告、标准设立、偏差或者项目功能差异(DIF)分析。他对教育机构提供给学生、教师、父母等的有指导信息的报告的程序和方式非常感兴趣。
瑞安博士学术成就卓著,发表了上百篇论文与多部重要专著。近年来他在教育测量与评价领域的重要著作包括:A practitioner’s introduction to linking and equating, ( the Council of Chief State School Officers,2010 );Practices, issues, and trends in student test score reporting, (S. Downing, T. Haladyana Eds.,2006 ); The Handbook of Test Development,(Lawrence Earlbaum Associates: Mahwah,NJ.,2006 );Large-scale assessment programs for all students: Validity, technical adequacy, and implementation, ( Lawrence Earlbaum Associates:Mahwah,NJ.,2002 )等。
#p#副标题#e#
导 言
笔者连续写作了三篇论文来审视测验等值和连接中涉及的概念、程序、应用以及碰到的问题等,本文是这一系列论文的开篇之作。本系列论文是面向开发、维护和改进教育测量项目的教育工作者所创作的,其目标读者群包括教育测量的用户、从业者以及负责教育测量项目的政策制定者。当然,对于其他想对连接与等值做一些基础的了解,从而进行更深入的技术学习的人士来说,这些论文也是非常实用的基础知识。
文中使用了许多教育测量的实例来说明涉及的概念与程序,这些实例和说明都是在美国以及世界其他地区常见的实践和方法。这些情况说明,在教育测量中等值已经发展成为了能够应用于特定的目标、满足特定要求的手段。然而,我们也需要认识到,这些教育测量的案例并非放之四海而皆准,而且其仅仅是说明性的而非规定性的。例如,这些论文很大程度上是以美国教育研究协会(American Educational Research Association,简称AERA)、美国心理协会(American Psychological Association,简称APA)和美国教育测量学会( National Council on Measurement in Education,简称NCME)编制的《教育与心理测试标准》(1999)为基础的,其中收录的内容都是一些得到了广泛认可的书面准则和教育测量中的惯例,但是其应用必须要和教育测量中的教育与文化背景结合起来。
#p#副标题#e#
一、等值与连接中的效度概念、测试目的与测试规范
(一)效度的概念
在所有的测评项目中,效度都是人们最关心的问题。在构建测评过程中的每一个阶段,人们都必须对效度证明作出正式的记录。《教育与心理测试标准》中给效度的定义是:“在测试目标要求之下,证据和理论能够支持对测试成绩进行解释的程度。”(AERA,APA,NCME, 1999,第9页)该标准还指出,“逻辑上说,效度测量开始于对测试成绩的解释给出明确的说明”,而且,这样的解释“需要能够体现测试意图考察的构想或者概念”(AERA等,第9页)。
在许多测评项目中,针对效度的此种观点可以这样理解:即要求考试开发者对学生需要在考试中掌握的知识和技能作出清晰、明确的解释,从而确保测试的可靠性。假如没有一个清晰、明确的对学生的要求,一项测试想要有效地衡量学生的学习水平虽然不是完全不可能,却也是相当困难的。
Linn(2008)阐述了效度的含义,指出虽然人们常常随意地讨论测试的效度问题,一项测试中真正有效的其实并不是测试结果本身,而是这一结果的应用、解读和要求:
也许一些证据可以说明,对测试结果特定的应用会得到较高的效度;然而,同样的一个测试结果如果用于其他的目的,就可能毫无效度可言。例如,某一项测试或许能够显示出学生在某一个特定领域内所具备的知识和技能,从而对制定教学计划有所帮助;但是如果把这项测试成绩用于颁发高中毕业证书这样的高风险决定时,它的效度就不够充足了。
Sireci(2009)针对效度这个概念的历史作过一个颇为有趣而发人深省的叙述,他对效度作了三个和Linn颇为相似的评论:
(1)效度并不是一项测试的内在属性;
(2)效度与对测试成绩作出的解读和应用息息相关;
(3)衡量效度必须要考虑到测试的目的和应用。
以上是笔者对目前有关效度的观点做的一个简要的综述,我们从中能够看出,目前主张把效度看作测试结果解读和应用中的一个属性。这和传统观点中把效度看作一项测试的特征大不相同,而且这对“等值”这个概念的理解和评估有非常重要的意义。
#p#副标题#e#
(二)测试目的
教育测评项目中的测试成绩通常含有多方面的目的,其中包括但不局限于以下方面:利用测试成绩增强教师教学、学生学习的效果;衡量学生取得的进步;评估不同课程体系和教学方法的效率。此外,将测试成绩与其他一些信息相结合,可以对学生未来的学术和其他成就作出预测。因此,要对两个不同的测试版本进行等值,实际上就是要求这两个测试版本能够同样有效、完满地实现该项测评的目的。
对于大规模的测试项目来说,等值是非常重要的。因为同一考试机构会使用大量不同的试卷,而且这些试卷每年(甚至更频繁)还都会有所变化。这样的测试项目面临的主要挑战在于,由于不同的测试版本所考查的内容和目的是一致的,它们之间的评分标准和意义需要保持一致。这就是对测试的效度提出的考验,因此在构建不同版本的测试时,保证测试成绩具有一致的解释并能一样完美地服务于相同测试目的是非常关键的。
(三)测试规范(test specifications)
在这一系列论文中,笔者所关注的焦点是测试等值与连接中技术上、心理测量上的概念和程序。然而,要想取得测试等值的成功,最有价值的步骤却不在统计或者心理测量的范围之内。事实上,测试等值中最关键的环节一是在于为不同的测试版本准备相似的题目;二是在不同的试卷版本中有同等的涵盖考查内容相同、认知水平相同、试题模式相同的题目。
编制试题和测试规范的活动本身就是一项制定规范的过程,而且这项活动所需要的东西往往会超出心理测量专家的经验和专业知识。在目前对于学生应该掌握的知识和技能所进行的系统性描述中,存在很多不同的框架。Bloom(1956)所著的《教育目标分类》也许是其中最知名的经典原型,在该书所提出的框架中,对学习的定义是从知识的认知过程角度进行的,包括:识记、理解、应用、分析、综合、评估。想要构建等值的测试版本,各个版本中就需要等量地涵盖考查以上几个认知层次的题目,而且所考查的内容也要相同。Anderson& Krathwohl(2001)在他们的大作《学习、教学、评估分类: Bloom的教育目标分类的修改》中,针对Bloom的观点提出了很有意义的补充。另外还有一些有影响力的机构和学者也提出了他们自己对学习分类的框架,包括美国教育进展评估(National Assessment of Educational Progress, NAEP)、Robert Marzano与John Kendall(2007)和Norman Webb(1997)等,这些框架都提出了一组与认知过程或知识内容有关的学习维度。
最关键的问题并不是该采用哪一种框架,而是人们必须编制出一套清晰、明确、通俗易懂的方法来说明试题和测试所考查的具体是什么,而且要将这一套说明方法当作编制试题和试卷的蓝本。假如不能对测试的考核内容作出清晰的定义,我们无法想象这个测试的效度将如何评价。
测试规范中除了内容和认知过程以外,还包括试题的形式和呈现方式。试题的呈现方式包括纸笔测试、计算机化测试(computer based administration of fixed test)和计算机适应性测试三种(Mills等, 2002)。试题形式则包括选择答案题型(如选择题、判断题、连线题等)、自拟答案题型(如简答题、延伸题等)和完成任务题型(如编制图表、完成实验等)。测试规范中有必要包括对试题形式和呈现方式的说明,这样一来,测试规范就包括学习内容、认知过程、试题形式和呈现模式四个部分。
对试题和测试规范的讨论并不总是出现在对等值与连接的论述中。然而,在试题命制的过程中尽可能地保持试题和试卷的相似性是实现等值的重要环节。如果不同的测试版本在内容、认知过程、试题形式、呈现方式上都很匹配,那么对成绩进行的等值实际上就是在试题命制阶段的“等值”的基础上进行的细微改良。反之,如果测试在以上几个重要方面都不相匹配,学生的测试成绩就会受到影响,等值操作仍然能够得出一个数字上的结果,但是这个结果却无法使试卷实现“等值”。
#p#副标题#e#
二、等值与连接:意义和困惑
(一)等值与连接的基本概念
“等值”(equating)是一个测量术语,指的是为了在两个及以上的测试版本的成绩之间建立成对关联,使之具有同样的意义而设计的一系列程序。在将两个不同测试版本的成绩进行等值时,包含两重意义:第一层就是简简单单地让不同测试版本的原始成绩或者衍生成绩之间可以转化、对应或者相提并论,从而能够替换使用;第二层意义则远不止对应成绩那么简单,它让不同的成绩通过等值后能够体现对考生知识、能力相同的解读和推断,而且在此基础上能够进一步采取相同的适当的行动。
等值是一个能够在同一项测试的不同版本之间构建具有相同意义的并可比较成绩的技术程序,有了它,不同的考卷就可以替换使用。只要进行过确实的等值操作,某个学生或者某组考生用哪一套试卷进行测试就变得无关紧要了。在许多大规模的测试项目中,等值都有非常关键的作用,因为这一类测试都需要使用不止一套试卷。在各种现实原因的影响下,同一个测试机构可能会使用大量不同的试卷。此外,试卷的形式也会逐年发生变化,甚至频率要更高。
人们对连接(linking)和等值(equating)两个术语经常混淆,有时还替换使用。连接是更广泛的术语,对两个测试版本建立相配或者成对的关系,并没有要求该成对的成绩具有相同的实质含义。连接和等值是不同概念,连接对成绩的解释能力弱于等值。人们的困惑有些可能源于它们两个都采用相同的技术步骤。同时,某些步骤如“等百分位等值”(equipercentile equating)已经成为测量和心理测量学常用的词组。连接测试即使采用“等百分位等值”也不一定导致形成等值的测试版本。
在连接与等值中,一份试卷得出的成绩要和另一份试卷的成绩建立相配或者成对的关系。换句话说,一份试卷的成绩需要转化到与另一份成绩相同的量表或者一份通用量表上去。例如,在标准型测试(standards-based assessment,t简称SBA,即以检验固定的标准内容为目的的测试)中得出的成绩,将能够连接或者对应到标准的常模参照测试(norm-referenced test,简称NRT)成绩上去。通过这样的连接,我们可以得到一个两列的表格,其中的每一行都将一个标准型测试(SBA)成绩与一个常模参照测试(NRT)成绩联系起来(反之亦然),这样就将两个测试成绩连接起来了,如表1。
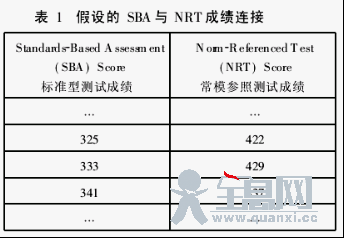
这样的连接可以用如下的短语进行恰当地描述:
“在标准型测试中得分为325的学生将极有可能在常模参照测试中得到422分。”“在常模参照测试中得到437分的学生很可能在标准型测试中得到341分。”
相比于仅仅将两个测试的成绩连接在一起,对两个测试所做的等值具有更强的意义。例如,如果我们成功地将一项于2009年进行的五年级数学考试与2010年进行的相同的考试等值起来,我们可以说:“就所考查内容的范围来说,在两次测试中取得相同成绩的学生所掌握的知识与技能的水平也是相同的。”
当我们说这两份试卷是“等值的”时,我们所表达的意思就是:它们考查的是相同的内容和认知程度,对学生掌握的知识、技能作出了相同的解读和推断。有了这些强有力的断言,我们就能够在包括一些对学生和其他人意义重大的测试中替换使用等值的试题版本。
但是,如果我们说两份试卷是“连接的”,那意义就大不一样了。连接能够说明不同测试的成绩之间是相互关联的,但是却无法说明这些测试具有相同的解读、推断以及成绩的互相使用是有效的。和连接一样,等值也可以说明两个测试之间的关联,但是它还具有更深一层的含义,那就是这一对成绩含有相同的实质意义。
要想区别连接与等值,我们可以把等值看做“连接”这个连续统一体上的一个极端,如图1所示。
这个连续统一体的右侧所表现出的,就是在有意构建的等值测试中所表现出的测量状况。此时,两个(甚至多个)不同的测试就可以正式沿着一定的程序进行等值(具体操作在本系列论文的另外篇章中将作交代)。针对同一内容、属于同一年级的测试将会被设计成尽可能的相似,这样一来所得出的运算数据就可以直接用于等值之中。图1的左侧所表示的则是另外的情况——两个不同的测试成绩的连接,此时,我们不能说某一个测试的成绩与另一个测试成绩具有相同的意义。
分布在这个连续统一体两端之间的,则是一些严格意义上说近似于等值的测量状况,但是这些状况仍不能完全满足等值的要求。Mislevy(1992)对这一分布作出了说明,他将测试之间的连接分成了四类:调整(moderation )、推算(projection)、校准(calibration)和等值(equating) (Mislevy,1992,第21~26页)。在他的模型中,调整是最弱的一类连接,而等值则是最强的,可以让不同的测试成绩最大程度地替换使用(这四个术语将在后面的文章中详细说明)。
如图2所示,右侧的等值是最强的一种连接,其他较弱的连接则都在图的左侧。在这个图中,达到等值一侧的连接需要更严格的要求,以使两个或者多个测试版本能够替换使用,那些无法达到这些严格标准的连接可以说是“像右侧运动”,但是仍旧不算是等值。
(二)等值与连接中的基本术语
这一部分中,笔者将对等值与连接中一些重要术语作简要的定义,以期能够用大众的、简单的语言来理解等值与连接中更多的细节。以下所有术语和程序都会在系列中的另一篇文章里作详细的论述。这里所收录的术语并没有网罗全部,主要集中于等值中所有最基础、最重要的术语和概念。
1.锚题、共同题、连接题(anchor items/common items/linking items)。这三个术语经常替换使用,在本系列论文中将通称锚题。所谓锚题,是指在两份或两份以上的试卷中出现的一组相同的题目。这些题目会像“锚”一样,起到稳定等值所需的测量量表的作用。这些在两份及以上的试卷中通用的题目还能够把不同的试卷“连接”到同一个量表上。
锚题的特征。锚题需要在内容和形式上与整个测试保持相近,还需要在题目顺序上与待等值的考卷相似。
增补锚题与嵌入锚题(appended and embedded anchor items)。出现在试卷末端的锚题是增补锚题,出现在试卷中不同位置的锚题是嵌入锚题。在等值中,嵌入锚题会比增补锚题发挥更大的作用。
锚题等值法。当使用锚题等值法时,等值方法包括等值常数法(the application of an equating constant)、固定校准法( the fixed calibration method)、同步校准法(the concurrent calibration method)、测试特征曲线法(the test characteristic curve method)等。
2.随机等值群(random equivalent groups)。这种随机选择学生参加不同考试的方法是一种很有价值的抽样方法。把从中得到的数据当做是同一个学生参加不同测试的情况,因而可以支持多种等值方法。
3.螺旋测试形式(spiraling test forms)。所谓螺旋,是指在一个学生群体(一个班或一所学校)内发放多种试卷形式。当不同的试卷(例如,试卷A、B、C、D)在同一个被测群体中随机发放时,往往就会出现螺旋。通常的做法是把不同的试卷按照比如ABCDABCDABCD这样的顺序放好,然后按顺序分发,拿到不同试卷的组群可以看做是随机等值组。
4.矩阵抽样(matrix sampling)。将题库中的题目分成不同的题组,再将它们分发给学生作答。不同的题组由不同的学生完成,这样每个人都不需要做完所有的题目,同时所有的题目都由足够多的学生做过了。这样的结果能够支持经典测量理论和项目反应理论的分析,也能够用于等值之中。
5.题库(item bank)。通常来说,题库指的是一组仔细归纳起来的试题,其中包括题目文字表述、阅读文段、图表、特别的题目属性、答案,以及从题目的预测和正式施测中得到的统计信息。在一个安全的题库中,只有命题人在命题时才能接触到其中的题目。也可以将一组题目或题库应用于平时测试、基准测验或者形成性评价。在等值的语境下,题库中的题目会以某种等值或连接的形式放置到一个通用的量表上。
6.预测(field testing)。预测是指用对学生进行不计分测试的方式检查试题的整体质量,并获得IRT题目参数的估计值。预测常用来开发原始题库和试用版的试卷。IRT值是否有用、建立在预测基础上的等值是否有效,这些都取决于预测和正式考试之间的相似度有多少。
7.多试卷版本、通用锚题(multiple forms, common anchors)。多试卷版本通常和一套通用的锚题一起使用。例如,如果需要等值的是试卷A、B、C和D,那么这四套题需要采用同一套锚题。
8.试卷间等值(form-to-form equating)。这种等值的方法就是将一系列试卷以两两结对的方式等值起来。例如,试卷A和试卷B可以由一套共用的锚题等值起来;试卷B和试卷C又可以由另一套共用的锚题等值起来;试卷C和试卷D也同理进行下去。理论上说,通过这种方法可以将所有的试卷都统一到一个测量量表上来。有时候它也被称做将所有的试卷“串联”起来。
9.横向等值(horizontal equating)。在大规模测试项目中最普遍的需求,就是在较长的时间里保持每个年级量表和行为评定标准的稳定。在同一年级或年龄阶段内的测试间进行的等值就是横向等值,横向等值是一种试卷间等值。
10.纵向量表化(vertical scaling)。纵向量表化是一个建立题库或者一系列试卷,使用等值程序建立跨年级或年龄的测试量表的过程。虽然它有时也称为纵向等值,但是在严格的等值定义下(例如应用环境和测试构念等值),它还达不到这样的要求。然而,如果把它看做不同年级测试之间的连接,则比较合适(Patz, 2007,第6页)。
11.预先等值(pre-equating)。预先等值是指利用提前确定的题目参数值,从题库中的题目里组建(construct)新的试卷的过程。新的试卷需要在IRT难度、内容、形式等方面符合测试规范的要求。在使用新试卷前,需要建立一张成绩对照表格,这张表格是基于现有的IRT题库值,显示量表的成绩和新试卷原始成绩的对应关系。
12.事后等值(post-equating)。事后等值顾名思义就是在学生参加测试之后对得到的成绩进行等值。事后等值最好取参加测试的全体考生的成绩进行,不过如果出成绩的时间要求比较紧,也可以选择一个“早期回收”(early return)的样本,但应选择一些有代表性的考生成绩进行。在时间和资源允许的情况下,我们强烈推荐使用事后等值而非预先等值。
13.试题参数偏离(item parameter drift)。当新试卷用到题库里或者别的试卷的试题时,通常会使用题目难度、区分度和猜测参数(后面将作介绍)的IRT参数估值,前提是这些参数保持稳定不变。然而在某些情况下,IRT参数值会发生变化或者偏离其题库值,而使用IRT方法时任何大的试题参数发生偏离都可能损害等值。试题参数偏离通常是在这种情况下发生的:题目已经使用了多次因而对目标考生群已经不陌生。
14.等值误差(equating error)。等值操作中的每一个步骤都会有来源不同的误差变量。除了试题参数偏离之外,还有试题本身的测量误差、样本误差、参数估算误差以及应用等值过程中产生的误差变量等。造成等值误差的变量来源很难确定,而且它们之间的关系是相互叠加而非相互消除的。以上是对笔者选出的若干重点术语、概念所作的简要介绍,在随后的文章中我们还会再次重点讨论。笔者将会通过更多的细节解释以上提到的术语、概念,也会继续介绍一些、解释一些新的术语和概念。有关连接与等值的细节问题的讨论可以参看Kolen与Brennan(2004),Holland与Dorans(2006),以及Dorans,Pommerich与Holland(2007)等相关文献。







